Riigikogu valimiste eel erakondade antud valimislubaduste kvantitatiivne tekstianalüüs
-

Rahandusministeeriumi fiskaalpoliitika osakonna juhataja
Iga nelja aasta järel toimuvad Eestis Riigikogu valimised. Erakondade valimisprogrammid on mahukad ning lubadusi antakse valimiste eel palju, mistõttu on nende terviklik hoomamine üsna keerukas ja nõuab tekstidesse süvenemist. Samal ajal on tänapäeval üha levinum erinevate masinõppealgoritmide kasutamine, et otsida tekstidest mustreid ja seoseid.
Pole võimatu, et järgmistel valimistel aitab valijal valimisprogrammidest vastuseid leida juba mõni vastav vestlustarkvara või juturobot.
Ehkki tekstianalüüsi algoritmid on erinevad, on nende üldine tööpõhimõte sarnane – matemaatiliste meetoditega otsitakse sagedamini esinevaid sõnu ning üritatakse leida statistilist seost koos esinevate sõnade vahel.
Selleks, et saada aimu, kuidas võiks masinõppe algoritmid Eesti valimislubadustest aru saada, ongi allpool kasutatud kvantitatiivset tekstianalüüsi. Viimase abil saab masinõppe ja andmekaeve meetoditega töödelda suurt hulka tekste ning leida seoseid, mida on muidu keerukas märgata.
Andmed
Andmekaeveks kasutasin rahandusministeeriumi poolt valimislubaduste analüüsi käigus kogutud 2397 valimislubadust, mis pärinevad seitsme valimistel täisnimekirjaga osalenud erakonna valimisprogrammidest. Iga valimisprogrammi lugesin arvutisse täistekstina lausete ja lõikude kaupa. Oluline on ka märkida, et rahandusministeerium salvestas valimisprogrammid erakondade veebilehtedelt veebruari alguse seisuga.
Metoodilist eeskuju analüüsi läbiviimiseks ammutasin mitmest allikast – nii tekstianalüüsi meetodeid tutvustavatest materjalidest kui ka teiste riikide sarnastest analüüsidest. 2019. aasta valimiste kontekstis on sarnase analüüsi veebis avalikuks teinud Martin Mölder, kelle toonase analüüsi loogikat kasutasin ka selle analüüsi puhul.
Kuna eesti keeles on palju käänd- ja pöördsõnu, lemmatiseerisin esimese sammuna kõik valimisprogrammid ehk viisin sõnad algvormile EstNLTK vastava vabavaralise teegi abil. Samuti eemaldasin eesti keele tüüpilised stoppsõnad (asesõnad, sidesõnad, küsisõnad jms) ja viisin kõik sõnad väiketähtedele. Stoppsõnade loendina kasutasin Kristel Uiboaia koostatud loendit. Lemmatiseerimise viisin läbi programmeerimiskeeles Python ning analüüsiks kasutasin tarkvarapaketti R koos mitme teksti- ja andmeanalüüsiks mõeldud teegiga.
Sõnade sagedusanalüüs
Esmalt uurisin, millised sõnad esinesid valimisprogrammides kõige rohkem. Ülekaalukalt kõige rohkem ehk ligi 900 korda on programmides kasutatud sõna „Eesti“. Paarkümmend kõige sagedamini esinevat sõna on toodud joonisel 1.
JOONIS 1. Sõnade sagedusanalüüs
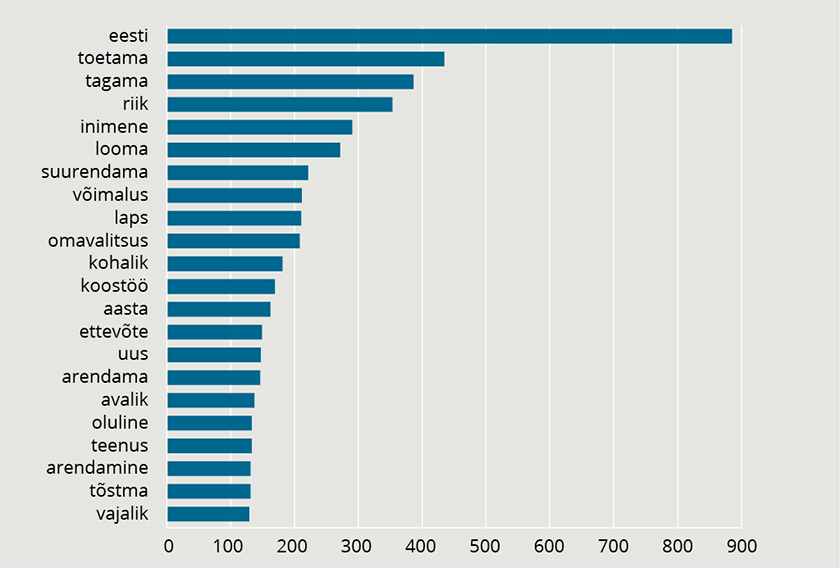
Seega räägivad valimisprogrammid kõige rohkem Eestist, riigist ja sellest, kuidas vastav partei toetab või tagab midagi. Samuti inimestest, millegi suurendamisest, lastest, võimalustest, kohalikest omavalitsustest, koostööst, ettevõtetest ning arendamisest, olulisusest, vajalikkusest, tõstmisest jne.
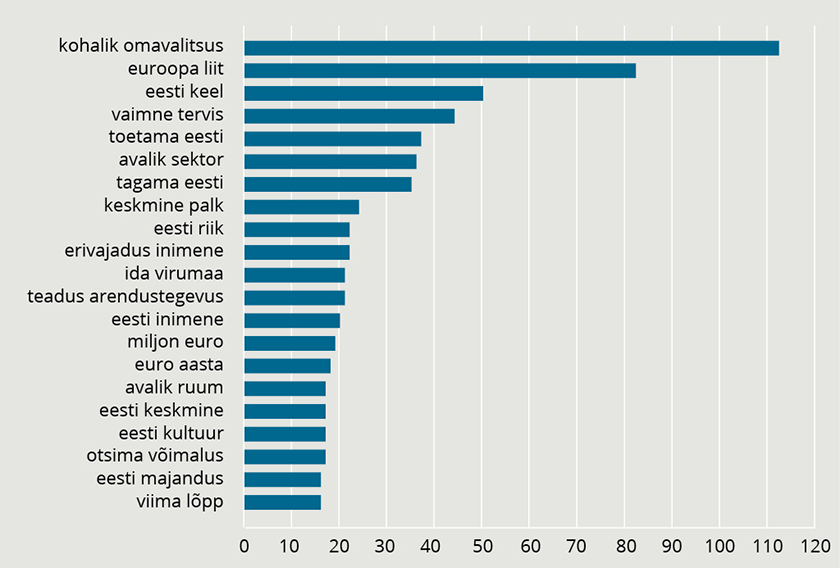
Tehes sarnase analüüsi kõrvuti koos esinevate sõnapaaride esinemissageduse kohta, saame joonisel 2 kujutatud tulemuse: kõige rohkem räägitakse valimislubadustes kohalikest omavalitsustest, mida on mainitud valimisprogrammides ligikaudu sada korda. Samuti Euroopa Liidust, eesti keelest, vaimsest tervisest ning sellest, kuidas toetatakse Eesti inimesi, elu või tegevusi ühel, teisel või kolmandal moel. Kõrgel kohal on ka keskmise palga, erivajadustega inimeste, teadus-arendustegevuse ja Ida-Virumaaga seotud teemad.
JOONIS 2. Sõnapaaride sagedusanalüüs
Sõnade koosesinemine
Seejärel vaatasin, millises kontekstis ehk milliste teiste sõnadega valimisprogrammides kõige rohkem kasutatud sõnad esinevad. Selleks kasutasin korrelatsioonanalüüsi, eristades seosed korrelatsiooniga üle 0,2.
Sõnade koosesinemise analüüsi tõlgendamisel on oluline vaadata jooniselt 1 ka analüüsitavate sõnade esinemisarvu valimisprogrammides. Juhul kui konkreetne sõna esines valimisprogrammides väga tihti, aga andmekaeve meetodid ei suuda leida keskmisest rohkem eristuvat konteksti selle sõna kõrvale, siis tuleb sellest järeldada, et vastavat sõna kasutati hästi paljude erinevate nähtuste iseloomustamiseks. Näiteks on üheks selliseks sõnaks „toetama“, mida kasutati valimisprogrammides üle 400 korra, aga mis sellest hoolimata ei eristu üheski konkreetses kontekstis. Seega kasutati sõna „toetama“ nii laialdaselt ja nii erinevates teemades, et see sõna ei seostu otseselt millegagi – põhimõtteliselt on parteid lubanud toetada ühtlaselt kõike, millest nende valimisprogramm räägib.
Sõna „laps“ kasutati seevastu üle 200 korra, kuid väga selgetes, aga siiski ka väga arvukates kontekstides.
Sõnal „Eesti“, mida kasutati ligi neli korda rohkem kui sõna „laps“, on tuvastatavaid kontekste aga oluliselt vähem. Seda tuleks tõlgendada nii, et sõna „Eesti“ kasutati samuti väga laialdaselt ja erinevates kontekstides, kuid siiski keskmisest rohkem seostatuna maailmaga, enesekindlusega, õnnelikkusega jne.
Omamoodi huvitav on täheldada, et kohalike omavalitsustega seonduv kontekst on mõnevõrra kantseliitlikuma keelekasutusega kui laste või inimestega seotud kontekst. Seega on valimisprogrammides varieeritud keelekasutust vastavalt auditooriumile.
Pikem nimekiri 15 populaarseima märksõnaga seotud konteksti kohta on järgmine:
- Eesti esineb keskmisest rohkem koos sõnadega maailm, enesekindlus, kõrgekvaliteediline, lasteriik, sisenema, õnnelikult, keel, majandus
- toetama1
- tagama2: sidevõrk, sideühendus
- riik: personaalne, digiajastu, mastaapne, riigiaparaat, riigisüsteem, riigivalitsemine, riigiteenus, kodanik
- inimene: õnnetunne, õige, terve, õnnelik, asutuspõhine, inimesekeskselt, elatud, tervisemure, puue
- suurendama (vt allmärkus 1 lk 193)
- võimalus: otsima
- laps: enesekindlus, kõrgekvaliteediline, lasteriik, sisenema, õnnelikult, pere, sündima, mängima, kasvamine, transpordisüsteem, turvaline, lasterikas, kese, tipptase, vanem, üritus, väärtustama, lastetoetus, ruum, tugi, helde, hool, kehvem, vajadus, vajaduspõhine, kodulähedane, kool, liikuma, lähtuvalt, kasvatav, sündimine
- omavalitsus: tulubaas, hajumine, endiselt, haldusterritoriaalne, initsieerima, maksukorraldus, omavalitsusreform, finantsautonoomia, laekumine
- kohalik: finantsautonoomia, tulubaas, laekuma, turismimaks
- koostöö: põhjamaa, dimensioon, erasektor, heauskne, hoolima, missioon
- ettevõte: edusamm, innovatsioon, trepiaste, trepp, majandusmudel, tööriist, ümberkujundamine, julgeolekuvajadus, kooskõlastamine, möödapääsmatu.
Teemade modelleerimine
Järgnevalt kasutasin tekstianalüüsiks teemade modelleerimist, mille puhul otsitakse tekstis sarnases kontekstis esinevaid sõnu ja üritatakse nii grupeerida valimislubadused väiksemateks alamteemadeks.
See, mitmeks teemaks lasta andmekaevemeetoditel tekst jagada, ei ole ühene ja on pigem analüütiku otsus, mis tehakse selle järgi, kui mõistuspäraselt on väljasõelutud märksõnade teemadeks jaotamist võimalik sisuliselt põhjendada.
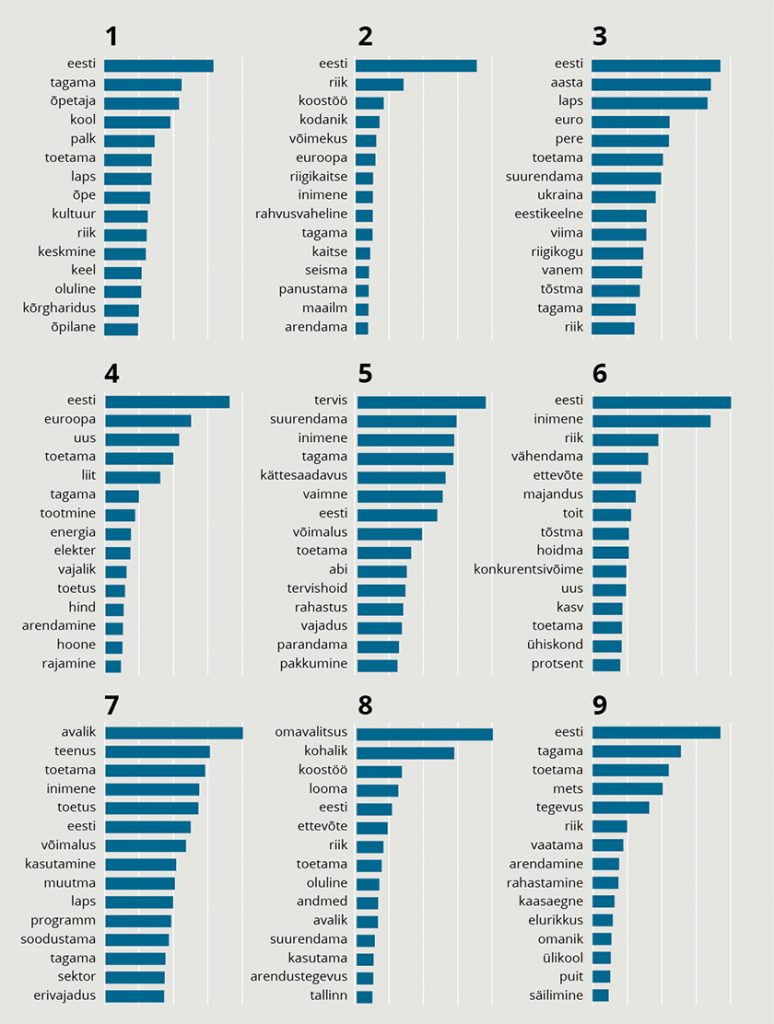
Antud juhul tundus mõistlik jaotada valimislubadused tinglikult üheksaks teemaks (vt joonis 3). Rohkemateks teemadeks jagamise korral hakkasid märksõnad omavahel juba mõneti raskemini tõlgendatavalt segunema. Antud näite puhul oleks 11 teemaks jaotamise puhul energeetika ning ettevõtete ja majanduse konkurentsivõime teema segunenud ning jagunenud nii, et oleks olnud kaks eraldiseisvat toetuste teemat (peretoetused ja hinnatõusuga toimetulek) ning energeetika teema, aga konkurentsivõime ja majanduse küsimused oleks segunenud peretoetuste ja hinnatõusu küsimustega.
JOONIS 3. Teemade modelleerimine. Sagedasemad märksõnad üheksaks teemaks grupeerimise puhul
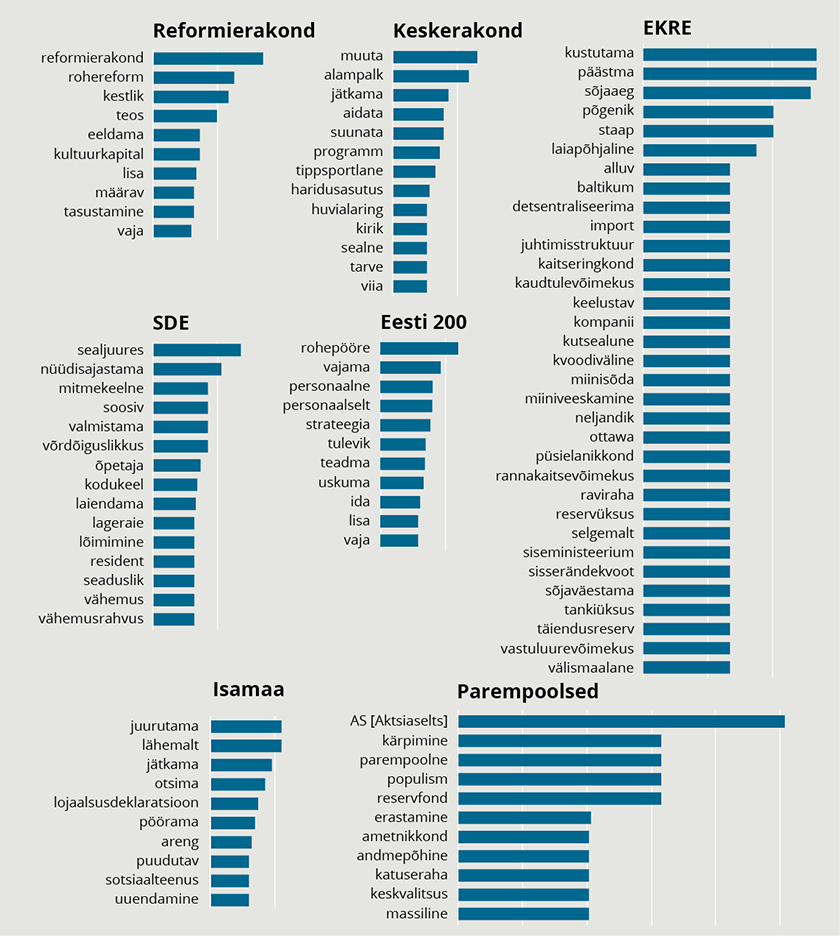
JOONIS 4. Kõige iseloomulikumate sõnade sagedusanalüüs erakondade kaupa rühmitatuna
12 teemaks jaotamise puhul oleks avaliku halduse teema omakorda jagunenud kaheks sarnaseks temaatikaks.
Järelduste tegemine leitud sõnadest on mõneti tinglik, kuid põhimõtteliselt võib siiski öelda järgmist:
- esimene teema on seotud koolide ja haridusega ning õpetajate palkadega,
- teine teema riigikaitse võimekusega ja sellesse panustamisega, hõlmates sealhulgas kodanikke ning rahvusvahelist koostööd,
- kolmas teema tundub olevat segu eesti keelest ja integratsioonist, ka seoses Ukraina lastega,
- neljas teema on seotud ELi energiateemadega, elektriga ja perede toetamisega kiire energiahindade tõusu kontekstis,
- viies teema on seotud tervishoiuga ja viitab lubadustele suurendada tervishoiuteenuste kättesaadavust, rahastust, ning vaimse tervisega,
- kuues teema on seotud majanduse ja ettevõtete konkurentsivõimega, riigi toetustega ettevõtetele, ringmajandusega,
- seitsmes teema tundub olevat seotud avalike teenuste tagamisega, sh erivajaduste kontekstis, omavalitsustega, programmidega,
- kaheksas teema tundub olevat seotud ettevõtete ja töökohtade loomisega väljaspool Tallinna ehk kohalike omavalitsuste koostöös,
- üheksas teema tundub olevat seotud metsanduse ja elurikkusega.
Erakondade sõnakasutus
Lõpetuseks koostasin sõnade sagedusanalüüsi ja koos esinevate sõnapaaride sagedusanalüüsi erakondade kaupa rühmitatuna. Tulemused on toodud joonistel 4 ja 5. Joonisel 5 on toodud sõnapaarid, mida on valimisprogrammis mainitud rohkem kui viis korda. Sõnade arv on erinev, sest viis korda lävendit ületavaid sõnapaare oli erinevatel erakondadel erinev arv.
Erakondadeks eristamise puhul on oluline märkida, et joonistel toodud tulemused on järjestatud vastava erakonna valimisprogrammile kõige iseloomulikumate sõnade järgi, aga see ei ole päris sama sõnade kasutussageduse järjekorraga. Nii näiteks olid Sotsiaaldemokraatliku Erakonna valimisprogrammis kõige sagedasemad sõnad „õpetaja“ ja „laiendama“ ning sageduselt kolmas sõna oli „sealjuures“. Aga kuna sõna „õpetaja“ leidus ka teiste erakondade valimisprogrammides, siis sellevõrra on vastava sõna tähtsust sotsiaaldemokraatide valimislubaduste eristamiseks alandatud. Seega tekstirobotite jaoks on Sotsiaaldemokraatliku Erakonna valimisprogrammi kõige iseloomulikum eristav sõna „sealjuures“.
JOONIS 5. Sõnapaaride sagedusanalüüs erakondade kaupa rühmitatuna
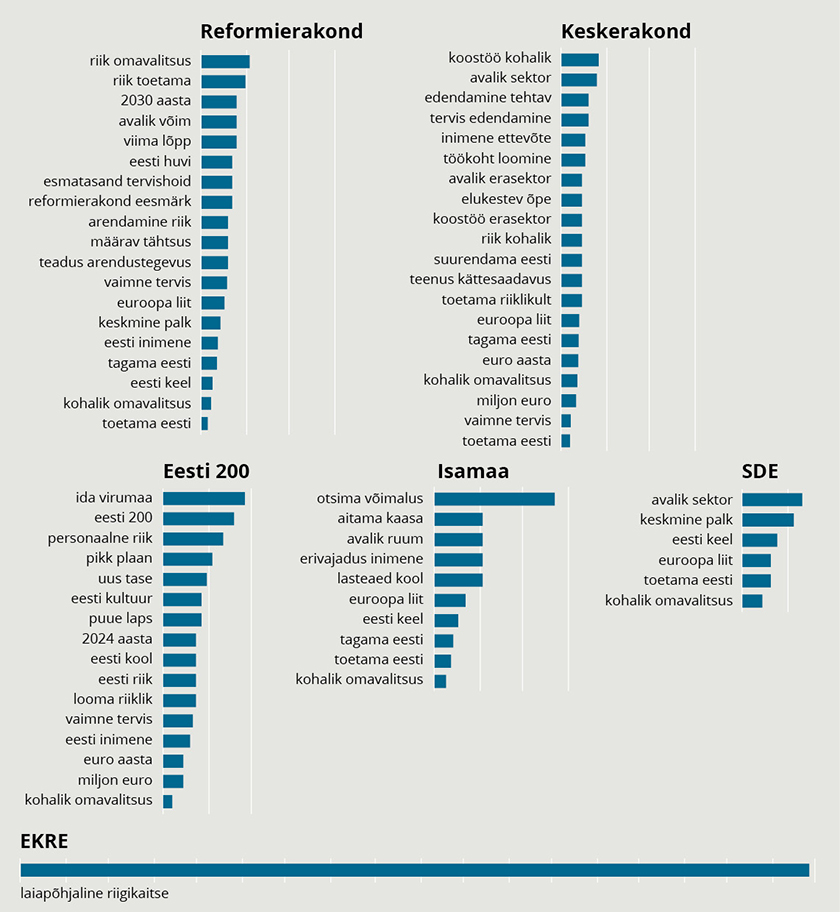
Samamoodi tuleks tõlgendada ka Eesti Konservatiivse Rahvaerakonna (EKRE) puhul eristuvat militaristlikku sõnapilve. Tegemist ei ole tingimata sõnadega, mida vastavas valimisprogrammis kõige rohkem kajastati. Kuid kuna erakonnal oli valimisprogrammi osana esitatud teistest oluliselt detailsem militaarvaldkonda käsitlev osa, on tekstianalüüsi vaatevinklist just need märksõnad kõige määravamad, mille järgi märgistada lubadus EKRE omaks.
Üldiselt ei ole aga erinevused sõnade esinemisarvu ja iseloomulike sõnade vahel eriti suured. Nii oli Reformierakonna valimisprogrammis mitte ainult kõige iseloomulikumaks, vaid ka kõige sagedamini esinevaks sõnaks „Reformierakond“, ning sõnapaaride puhul „Ida-Virumaa“ kõige sagedamini kasutatud sõna Eesti 200 valimisprogrammis.
Kokkuvõte
Ühest kokkuvõtvat järeldust sellisest analüüsist on loomulikult väga raske teha. Pigem tuleks analüüsi vaadelda põneva peeglina valimisprogrammide keelekasutuse kohta ning võtta tulemusi nii, et just umbes sellises võtmes ja selliste märksõnade kaudu lahkavad, märgistavad ja eristavad erakondade valimisprogramme tekstirobotid ja otsingumootorid, mille kasutus meie ümber on igapäevaselt kasvamas.
Kasutatud allikad
- FEINERER, I., HORNIK, K tm. Text Mining Package, R package version 0.7-8, 2020. – https://CRAN.R-project.org/package=tm
- GRÜN, B. ja HOPRNIK, K. topicmodels: An R Package for Fitting Topic Models. – Journal of Statistical Software, 2011, nr 13, 40. köide, lk 1–30.
- HOLSTER, J. D. (10. juuli 2022). Introduction to R for Data Science, A LISA 2020 Guidebook. –https://bookdown.org/jdholster1/idsr/
- LAUR, S., ORASMAA, S., SÄRG, D. ja P. TAMMO, P. EstNLTK 1.6: Remastered Estonian NLP Pipeline, teoses Proceedings of The 12th Language Resources and Evaluation Conference, Marseille, France: European Language Resources Association, mai 2020, lk 7154–7162. – https://www.aclweb.org/anthology/2020.lrec-1.884
- LÄTTEMÄE, R. fpoplot: Themes, Colors and Tools for Making Charts in the Estonian Government Style, R package version 0.1, 2022.
- MÖLDER, M. (18. veebruar 2019). Valimisprogrammide kvantitatiivne tekstianalüüs. – https://martinmolder.com/blogi/valimisprogrammid2019/
- R CORE TEAM. R: A Language and Environment for Statistical Computing, versioon R version 4.0.3 (2020-10-10). R Foundation for Statistical Computing, Vienna, Austria, 2020. – https://www.R-project.org/
- ROBINSON, D. ja SILGE, J. widyr: Widen, Process, then Re-Tidy Data, R package version 0.1.5, 2022. – https://CRAN.R-project.org/package=widyr
- SILGE, J. ja ROBINSON, D. tidytext: Text Mining and Analysis Using Tidy Data Principles in R. JOSS, 2016, nr 3, 1. köide. – http://dx.doi.org/10. 21105/joss.00037
- UIBOAED, K. (19. aprill 2018). Eesti keele stoppsõnad. – http://dx.doi.org/10.15155/re-48
- WICKHAM, H. ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York, 2016, ISBN: 978-3-319-24277-4. – https://ggplot2.tidyverse.org
- WICKHAM, H., AVERICK, M., BRYAN, J., CHANG, W., McGOWAN, L. D., FRANCOIS, R., GROLEMUND, G., HAYES, A., HENRY, L., HESTER, J., KUHN, M., PEDERSEN, T. L., MILLER, E., BACHE, S. M., MÜLLER, K., OOMS, J., ROBINSON, D., SEIDEL, D. P., SPINU, V., TAKAHASHI, K., VAUGHAN, D., WILKE, C., WOO, K. ja YUTANI, H. Welcome to the tidyverse. – Journal of Open Source Software 2019, nr 43, 4. köide, lk 1686.
1 Loendit ei ole välja toodud, sest sõna kasutatakse väga laias kontekstis ning selgelt eristuvaid sõnapaare ei ole.
2 arvestades sõna „tagama“ esinemissagedust, kasutati ka seda pigem üsna laias kontekstis. Lihtsalt sideühenduste puhul on tuvastatav keskmisest mõnevõrra suurem korrelatsioon.